

Как Google и Facebook вычистят порно со своих ресурсов?
Начиная с июля компании Google и Facebook начали активно выживать взрослый контент с подконтрольных им территорий. Вряд ли Цукерберг договаривался с Пейджем чтобы провести атаку на порно синхронно, зато волна возмущения, поднявшаяся в ответ, получилась одной на двоих. Порядочные рекламодатели на Facebook не желают, чтобы их баннеры светились рядом с чьими-то телесами (были прецеденты), а Google, похоже, боится вредоносного софта, который через левые баннерные сети попадает внутрь гугловского периметра.
Прежде чем перейти непосредственно к теме сегодняшнего рассказа, позвольте предложить вам маленький эксперимент. Уберите на всякий случай от экранов детей и коллег и внимательно посмотрите вот этот ролик. Каюсь, он валялся у меня почти год, но всё как-то не было повода, а самое главное — не хватало смелости его показать.
Длится он семь минут, на протяжении которых девушка приятной наружности будет читать вам текст на английском языке. Даже если вы не понимаете английского, ради чистоты опыта наберитесь терпения (да, и я прошу вас не смотреть пока комментариев). Постарайтесь быть максимально объективным. А когда посмотрите, попробуйте определить: что вы только что увидели?
Симпатичная молодая особа читает какую-то книгу. Поведение её несколько… нестандартное, однако это можно объяснить характером текста (у неё в руках произведение «Necrophilia Variations», что-то вроде «Лица некрофилии»; без всяких ограничений предлагается, например, с Amazon.com, и рецензии, кстати, восторженные) и тем, для чего она это делает (снимается серия экспериментальных роликов под общим названием «Истерическая литература»). Вот и всё. Но теперь позвольте задать следующий вопрос: можно ли причислить увиденное вами к порнографии или хотя бы к материалам для взрослых?

Тот самый ролик
Чтобы облегчить задачу, приведу здесь стандартную памятку по классификации «контента для взрослых» (то, что называется adult) от одной очень крупной компании, чьё имя пусть останется за кадром. Итак, adult-контент — это:
– непристойные или провокационные изображения (в том числе изображающие людей в вызывающих позах, а также изображающие крупными планом грудь, ягодицы или промежность);
– материалы, содержащие грубую или ненормативную лексику, в том числе эротические рассказы;
– сексуальные советы или рекомендации;
– сайты, посвящённые сексуальному фетишизму;
– эротические игрушки и продукция;
– объявления или ссылки на другие сайты с содержанием для взрослых.
Подпадает ли увиденное вами под какие-то из этих пунктов? Промежностей и, простите, сисек не было. Игрушек, чулков, каблуков тоже. Ни ссылок, ни рекомендаций. Был текст, вроде бы принадлежащий к грубой порнографии, но, повторюсь, на Амазоне он лежит безо всяких возрастных ограничений, и отзывы к нему просто изумительные. Так что в общем и целом признайте: если и можно считать этот ролик «взрослым», то с очень большой натяжкой. Да на центральных телеканалах в прайм-тайм и в любом глянцевом журнале сегодня больше непристойностей и обнажёнки!
А теперь забудьте на минутку об увиденном (мы вернёмся к нему позже). Вы наверняка слышали, что в конце июня порнографии была — в который раз уже! — объявлена война. Только на сей раз не моралистами от церкви, не законодателями, периодически подбивающими клинья, чтобы засунуть индустрию для взрослых в интернет-гетто и никогда уже больше оттуда не выпускать, не родителями, обеспокоенными психическим здоровьем детей. Война была объявлена держателями двух крупнейших рекламных площадок Веб. Начиная с июля компании Google и Facebook начали активно выживать взрослый контент с подконтрольных им территорий.
Google занялась чисткой принадлежащего ей ресурса Blogger. Это один из самых ранних блог-порталов Сети, основанный аж в 1999 году и приобретённый поисковым гигантом четырьмя годами позже. К настоящему моменту там значительно больше ста миллионов блогов (вы натыкаетесь на них по адресам *.blogspot.com), и, естественно, есть среди них и такие, что содержат adult-контент. Google, впрочем, не против собственно материалов для взрослых, но с июля изменила правила ресурса, запретив пользователям на таких материалах зарабатывать. Попросту, если ваш блог на Blogger классифицирован как «adult» и вы вставляете на свои странички рекламу, знайте, что сегодня ночью он может быть удалён.
Что касается Facebook, она обещает пометить в своей соцсети всё «взрослое» и содержащее элементы насилия, чтобы больше никогда не размещать там рекламу. Удалять пользовательские странички не будут.
Вряд ли Цукерберг договаривался с Пейджем чтобы провести атаку на порно синхронно, зато волна возмущения, поднявшаяся в ответ, получилась одной на двоих. Не стану перечислять здесь всех контраргументов: кто-то боится за свой блог, а кто-то за Веб, которая по вине Blogger в одночасье останется без сотен тысяч «жежешэк» (и с бесчисленным множеством сломанных гиперссылок); третьих волнует, что взрослый контент вроде как оказывается на обочине, отделённый от рекламных потоков. Google и Facebook можно понять: порнография и эротика легальны, но портят им бизнес.
Порядочные рекламодатели на Facebook не желают, чтобы их баннеры светились рядом с чьими-то телесами (были прецеденты), а Google, похоже, боится вредоносного софта, который через левые баннерные сети попадает внутрь гугловского периметра. Однако нужно понять и авторов «взрослых материалов»: больше всего они опасаются волюнтаризма и неясностей — которые неизбежны, когда речь идёт об adult-контенте.

Дело в том, что Google сама, исходя из собственных представлений, лепит на Blogger-журналы метку «adult». Точно так же намеревается поступать и Facebook — в первое время вручную, а к осени и в автоматическом режиме детектируя материалы для взрослых. Но можно ли решить эту задачу математически? Да что там, может ли справиться с ней человек?
Возьмусь утверждать, что именно автоматическое обнаружение «взрослого» контента остаётся величайшей нерешённой задачей ИТ. И когда Facebook скромно обещает «мы построим автоматический детектор … спорного контента», когда Google берётся за прополку своего блог-пространства в полуавтоматическом режиме, они ступают на ту же зыбкую почву.
Программных продуктов, якобы способных уверенно отличать материалы без возрастных ограничений от тех, что ограничений требуют, на рынке всегда было предостаточно. Разве что десять лет назад они едва справлялись с задачей, а сегодня исследователями наработан новый класс алгоритмов, обеспечивающих — по крайней мере в лабораторных условиях — 94 процента попаданий и 5 процентов ложноположительных срабатываний (раньше порнографику обнаруживали по ключевым словам и характерному телесному цвету отдельных пикселей, нынче используютпиксельные «фразы», то есть сочетания точек).
Тем не менее и сегодня даже самые совершенные из практически применяемых порнофильтров всё так же готовы задержать фотку грудничка и пропустить сиськи. Например, Google Images с включённой «безопасной фильтрацией» в потоке изображений по запросу «конец» нет-нет да и пропустит что-нибудь вроде показанного ниже. А искать по слову «киска» вообще отказывается. Видимо, чтобы не позориться.
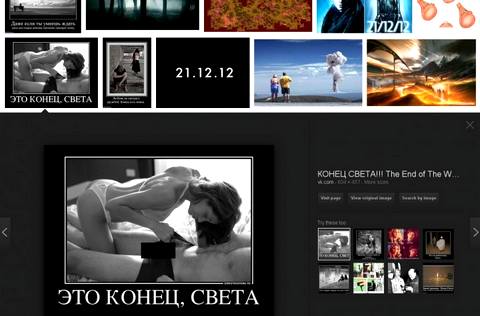
Google Images, фильтрованный поток по слову «конец» (цензура моя. — Е.З.)
Хуже всего, однако, то, что информации, содержащейся в самой контент-единице, часто бывает недостаточно, чтобы однозначно определить её принадлежность к той или иной категории. Вернёмся к нашему эксперименту. Опираясь на то, что вы видели, можно ли категорично заявить, что ролик был порнографическим? Едва ли. А если я сообщу вам больше?
Во-первых, текст читает Stoya, известная порноактриса. Во-вторых, читает она со вставленным между ног вибратором, уж простите за такую подробность, и поведение её есть прямое следствие действия этого устройства. Зная всё это, готовы ли вы причислить ролик к категории «18+»? Полагаю, да (впрочем, готов выслушать аргументы против). И это только один пример того, почему мало уметь распознавать обнажённое тело и даже понимать смысл, а необходимо учитывать ещё и контекст.
Вряд ли на такое способна хоть одна вычислительная машина. И даже человек рано или поздно допустит ошибку, если речь идёт об оценке достаточно большого объёма информации. А ведь именно это предстоит проделать сотрудникам Google и Facebook! Трудно не согласиться с критиками, которые опасаются, что под нож попадут блоги и страницы ни в чём не повинных художников, писателей, обозревателей, правозащитников, популяризаторов, учителей.
Не зря, ох не зря Yahoo! отказалась чистить порнографию на недавно купленном Tumblr. Может выйти себе дороже.
Автор: Евгений Золотов, КОМПЬЮТЕРРА
Tweet










